Introduction
What is configuration in Linux? What do experienced system administrators
do when they need to, for example, modify the access rights to a web
site or change the network settings for their server? Invariably, they're
going to login into the machine and edit a text file using a Unix editor
such as vi or Emacs. That by itself isn't that bad, but
depending on which application you want to configure and which Linux
distribution you happen to be using, the location of the file you
need to edit and maybe even the format of the file could be completely
unknown.
This is the current state of configuration in Linux. It is a bad state.
Configuration of system-level properties, such as network interfaces
and hostname, vary widely from one distribution to the next.
System-level applications, such as Apache and Samba, each have a
different method of configuration. Some
tools and distributions provide applications to ease configuration, while
some only provide a man page for the configuration file and leave it up
to the user to edit. About the only positive thing about Linux configuration,
is that is almost exclusively uses human-readable, human-editable text
files.
This article is not going to talk about the existing state of configuration,
however. This topic has been well discussed already. Instead, this article
will describe what it could be. This article is a kick-off
to a 9-month, 2-person project to address configuration in Linux.
Hopefully, it won't be limited to 9 months or 2 persons though.
We invite your feedback and participation in this project as we go.
Goals/Requirements
In order to develop a system that people will use and give direction to
the project, some goals need to be defined. The primary goal is to setup
a clear architecture where various components of the system are clearly
defined and separated. This is what this document will attempt to do.
Following are some more specific goals, categorized into user requirements,
data requirements, process requirements, and interface requirements.
User Requirements
- The system should be easy enough to use and provide enough help that
new Linux users can use it.
- The system should be flexible and powerful enough that even
advanced users will use it.
- Administrators should be able to delegate access to various components
of system configuration to other users (i.e. you should not need to
give out the "root" password to give someone access).
- Application developers who want to make their software configurable
by this system will not modify their existing application or make their
application dependent on it.
- The system will be uniform across distributions. For example, a script
written to update network configuration on RedHat will work properly
if run on Debian, because the interface is the same.
- Internationalization and localization should be stressed throughout
the project, so users from anywhere in the world can use their own
languages to configure their systems.
Data Requirements
- Configuration data is stored in the native configuration files for
the applications they configure. This allows the system to work with
existing configuration applications, as well as allowing the users
to hand-edit the files if necessary.
- Other data used by the system is stored in human-readable, human-editable
files.
- Mechanisms should exist to keep secure data secure and to backup/restore
data.
Process Requirements
- The most obvious process that needs to be available are methods to
"get" and "set" configuration data.
- Some configuration systems may need additional user-defined actions,
such as an "activate" action which will tell the appropriate application
to reload itself so that the new configuration info is used.
Interface Requirements
- Support the ability for many different type of applications to access
the configuration data using this architecture. Interfaces
would include a command-line program, GUI using Gnome or KDE, a Web
interface and perhaps even an LDAP interface.
- Programming interfaces between components should allow the different
components to be written in any programming language.
- User-interface elements for configuration (e.g. the forms and wizards
as described below) are defined at a level below the very front-end so
that multiple interfaces can use the same elements.
A Three-Tier Architecture
The architecture will be divided into many front-ends, a middle-layer, and
many back-ends. The front-ends will provide the user interface. This will
allow command-line utilities that can be used in scripts, GUI interfaces
for machines that have X installed, as well as remote interfaces such as
Web and LDAP. The middle layer will provide shared functionality between
the front-end interface and the back-ends. It could also be given
capabilities like logging
changes, access control, and caching configuration info. Finally, the
back-ends are the programs that actually read and manipulate the native
configuration files. There may be backends for reading XML files and Win INI
style files, as well as specialized backends for reading more complex
configuration files (e.g. Apache).
The Three-Tier Architecture
| Front-Ends |
| Command Line Utilities |
GUI |
Web |
LDAP |
Specialized Tools (e.g. "go back" utility) |
|
| Middle |
| Provides access control, logging, caching, and any other
shared functionality, as appropriate. |
|
| Back-Ends |
| Simple text files |
INI-style configuration |
XML configuration |
Specialized configuration
(e.g. Apache, Sendmail) |
|
How the layers communicate exactly is something to be decided in the
design phase, but it should be something that will allow each front-end
and each back-end to be written in any particular programming language
that is best suited for the task. Perl, for instance, would probably be
best suited for most of the back-ends, since it can easily parse and
modify text files.
Modeling the Configuration Data as a Directory
One major feature of this three-tier design is that front-ends are
designed to handle configurating anything. In other words, the front-ends
know nothing about the programs and distributions they are configurating;
they only provide an easy-to-use and consistent view of the configuration.
How can you tell the front-end that you want to modify, for instance, the
list of users that are allowed to access one of your Samba shares? This
is where the directory approach comes in.
Configuration will be modeled as a directory, or hierarchy, similar to
the way GConf and the Windows registry does configuration. Applications
and system settings will be put into logical groups. Back-ends will be
responsible for handling configuration "underneath" a particular branch
of the directory.
A proposed hierarchy
| Path |
Description |
| / |
All configuration for the local machine is done under the "root".
This root itself could be placed into another directory, which would
be important for remote administration. |
| /apps |
Contains configuration defining how some system applications run.
These are not daemons--meaning they don't run all the time. Examples
might include sudo and Debian's apt-get. |
| /daemons |
Contains system applications, such as Apache, sendmail and Samba. These
are applications that normally run in the background, and are equivalent
to "services" in MS Windows. |
| /daemons/samba |
This is where the back-end of Samba would exist. Anything under this
path will be handled by the Samba back-end, which would be responsible
for mapping the configuration of smb.conf into a directory. |
| /hardware |
Contains properties to configure hardware (e.g. sound card module
and network card IO address and IRQ number). |
| /network |
Configures network interfaces (e.g. IP address and default gateway). |
| /system |
Contains system-level settings, such as hostname, default runlevel,
and boot-loader settings. |
| /users |
Manage addition/modification/deletion of system users and their
properties. |
Particular configuration locations are not fixed. Users should be allowed
to rename, move around, or group system applications if they choose.
As applications are installed, they will be placed in a suitable default
location. Localization should be considered as well, so applications
can be grouped using words from a user's native language.
Users should also be able to create second copies of some applications,
in case they want to run more than one version of the same application
and they have more than one configuration file to edit.
Forms, Wizards, and Metadata
The system described so far does not present an interface much different
than the registry presents in Windows. If you want to make a modification,
you must navigate through a hierarchy and know the name of the attribute
you want to add or modify. This is probably worse than editing the
configuration files, because with configuration files you at least have
the comments that were built in. This is where forms, wizards, and metadata
come in.
Forms
Forms will give users a window where they can see the important information
and edit it using text boxes, list boxes, buttons and other common controls.
The information is presented in an organized way and may be split into
multiple tabs or pages if there is a lot of data to present. Forms can
probably be best thought of as providing an interface like Webmin in order
to modify configuration.
Forms are defined using an implementation-independent language, such as
XML Forms. The same form definition files could be used to create dialog
boxes and web pages. Forms are distributed with a program that supports the
configuration system, or they may be provided by a third-party.
As new versions of a particular distribution or system application are
released, the forms may need to be updated to support new features.
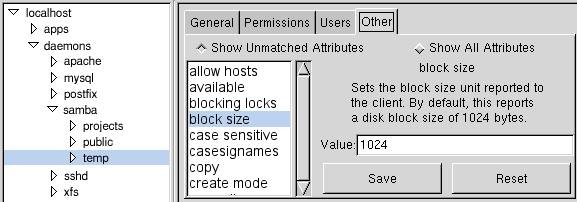
Here is a screenshot of a prototype of what a Samba share form might
look like. Notice how the properties for this share are organized into
four tabs, one of which is a generic "Other" tab which is capable of
showing all properties. On the "General," "Permissions," and "Users" tabs,
the application will show a form based on an XML form definition file
that describes a layout of controls and bounds the data on the form
to certain attributes of the Samba share.
Wizards
While forms allow users to manipulate existing configuration data,
wizards will give users oppurtunities to add things to the configuration.
Take for example, adding a Samba share: adding a Samba share requires
not just changing an attribute but rather adding a whole section to the
configuration file. Wizards will ask the user all the information needed
to create something and then perform the steps necessary to do it.
Wizards overlap somewhat with forms, because they will probably ask for
the same information that the forms manipulate. Wizards, like forms, can
probably be defined using XML Forms.
Wizards could also be created to install entire services. If integrated
into a particular distribution, you may be able to use a wizard to add
Samba to your computer. The wizard will use the facilities provided by the
distribution to download and install Samba onto your computer, and then
create an appropriate default configuration file.
Metadata
Finally, metadata is information about the configuration data.
Metadata could include the following items:
- Descriptions of configuration items (e.g. excerpts from the application's
manpages).
- Data type and constraints (e.g. this attribute must be a filename;
another attribute can be any string). XML Schema may provide a
language for this.
- Default values
- Comments in the configuration files as parsed by the back-end.
- Access Control Lists, for defining who has what type of access
to the configuration.
- History Log, for keeping track of what changes were made and who
made them.
Of course, metadata will be available to the front-ends. The front-ends
with a higher level of user interaction may wish to display descriptions
of the items and the comments associated with them.
Access Control
Access control defines who has access to read and/or change particular
parts of the configuration. Access control will allow the root user
to delegate out control of the configuration to other users. This is
important if more than one person is to administer a system, because
a person who only needs to manipulate user accounts may not want access
to the whole system.
Access control could potentially be quite flexible. In the traditional
Unix filesystem, files and directories have three types of permission and
can be applied to the owner of the file, a group, and everyone. While
pretty flexible, it has certain limitations, such as giving two groups
different levels of access while still denying access to everyone else.
An access control language for Unix configuration could be much more
flexible, allowing access to any number of users and groups and also
allowing very detailed types of access.
Access control is also useful when you start talking about logging, because
it allows users to make changes as themselves instead of as root.
Logging
As users make changes to the configuration, it should be logged. The log
could contain a date, the change that was made, and the user that made
the change. If it is a remote access method, the IP address of the connecting
machine could also be recorded.
A rich logging system would allow the creation of utilities that can
"go back" to previous states of configuration. If someone made some changes
that messed up the system, a "go back" utility could be used to revert
the configuration to the state it was in just before those changes were
made.
This "go back" utility would exist as a front-end, just like the command-line
interface and the GUI interface. It wouldn't know anything about how to
manipulate the configuration files; it would only know how to access the
list of changes that were made and revert them.
Remote Administration
In the world of Unix, managing a computer remotely is easy, thanks to the
wonders of SSH and remote X. For many users, these methods of remote
administration may be enough. But for those administrators who manage
a lot of servers, we may be able to provide for them as well.
Imagine a single program that you can browse to multiple machines with
and edit their configurations from that single program. This program
will handle connecting to the appropriate servers automatically and providing
the proper credentials to access the configuration.
Furthermore, imagine that when there's a new exploit for BIND, you do
a search for all BIND programs (from all the servers in your organization),
disabling them all in one keystroke, applying the patch, and re-enabling
BIND on all of them.
Configuration Data Distribution
Remote administration could be taken to the next step by storing multiple
copies of a computer's configuration on different servers. The primary
source of the data remains the computer that the configuration data is
for, but secondary copies could automatically be kept on "peer" servers.
This provides the unique ability to access configuration data when
the server in question is down.
Furthermore, what if you were allowed to modify the configuration data
when the computer is down? The modified data will be kept on the "peer"
computer and when the original computer comes back up, it will have
to synchronize. The synchronization could lead to critical changes so
it may be best to synchronize before any daemons are started.
The ideas presented here about remote administration and data distribution
are quite idealistic, and outside the initial scope of this project.
These ideas will give the project something to aim for, though.
Where to Start
At this point we'd like to get feedback from the Linux and Open Source
community. We'd like to answer questions like:
- Is this something worth striving for?
- Is it necessary to start from scratch or can one of
the existing configuration programs (e.g.
LinuxConf, WebMin) incorporate some of these ideas?
Addressing details like what programming languages should be used and
how to interface the various components are not necessary right now.
These things will be decided later, during the design phase.
We'd also like you to visit our project site at SourceForge. Go to
http://config4gnu.sf.net/.
|